




I am a data scientist at the Laboratory for Innovation Science at Harvard. I like Python and natural language processing and machine learning and data visualizations.
Skills

Python

R
SQL

TensorFlow

Keras

PostgreSQL

Bokeh

Heroku
Github

Git
Plus, I have experience with:

Flask

Django
JavaScript

MongoDB

HTML

CSS

Education
M.A. Computational Social Science
University of Chicago; 2016-2018
B.A. Economics and German Studies
Brigham Young University; 2009-2014
Projects
A Comparison of Methods to Predict Multisite Gasoline Prices -- Advisor: Luc Anselin
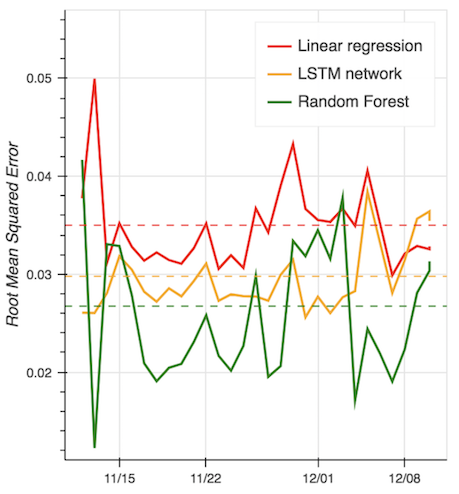
The goal of my master's thesis is to test the accuracy of three forecasting methods on a multisite time series prediction problem. Multiple linear regression, random forest, and long short-term memory (LSTM) network models were used to predict the price of gasoline at each of 12,374 stations across Germany every day for 30 days. I found that the random forest model outperformed the multiple linear regression and LSTM network models on average across all stations and days.
Evolving Character Relationships Using HMM and LSTM
The purpose of this project is to use book synopses to predict whether character relationshhips are cooperative or uncooperative. This is based off of work by Snigdha Chaturvedi et al. (2015) in which evolving character relationships are modeled by training a second order Hidden Markov Model on key text features. Our group recreates the feature extraction and modeling and extends it by also using LSTM neural networks to capture character relationships.
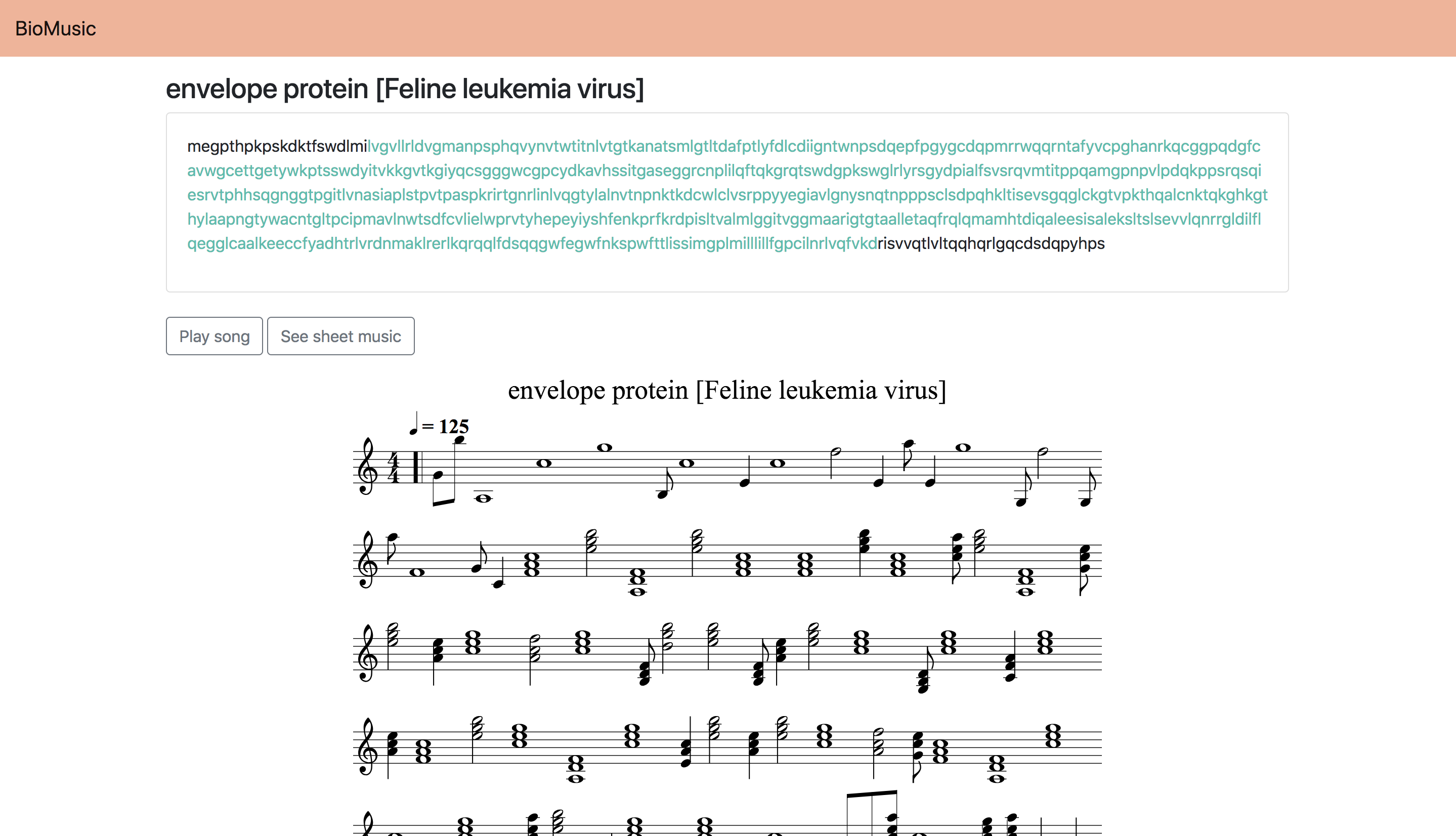
BioMusic
This Flask app explores protein sonification-- that is, the translation of protein sequences to music. We use the NCBI API to obtain the protein sequence and positions of the conserved domains within the sequence. Key signature, tempo, notes, and chords are determined by the amino acids in the sequence. Duration of notes is determined based on the overall distribution of amino acids in the protein sequence. Sections of the protein which are conserved domains are represented with chords.
Open Source Macroeconomics Lab Data Visualization
I created open source modules and data visualizations for large-scale macroeconomic models using Python's Bokeh package and JavaScript.
Very Fun Tweets
This is a fun Django app that collected streaming Twitter data for two months and detected which hashtags were spiking in use on Twitter. The algorithm to detect the spikes relied on moving averages and the plots were made using Highcharts. This project also gave me experience with both MongoDB and PostgreSQL as well as the Twitter streaming API.
